Motivation
Open-vocabulary (OV) 3D object detection for indoor scenes has mostly relied on point-cloud inputs, which require costly 3D sensors and limit deployment. In contrast, multi-view image–based methods have recently achieved strong fixed-vocabulary 3D detection but do not support open vocabularies. OpenM3D closes this gap: it is the first multi-view, single-stage OV 3D detector trained without human annotations. Built on geometry-shaped voxel features from ImGeoNet, OpenM3D learns to localize objects with class-agnostic supervision from high-quality 3D pseudo boxes and to recognize open-set categories via a novel Voxel–Semantic Alignment that matches 3D voxel features with diverse CLIP embeddings sampled from multi-view segments.
During inference, OpenM3D needs only multi-view RGB images and camera poses—no depth maps and no CLIP computation—making it highly efficient (~0.3 s per scene) while outperforming strong baselines such as OV-3DET and OpenMask3D on ScanNet200 and ARKitScenes in accuracy and speed. This brings practical, scalable OV 3D perception to applications like robotics and AR, without the overhead of expensive sensors or manual labels.
Method
OpenM3D is a single-stage open-vocabulary (OV) multi-view 3D detector trained without human annotations. It adapts ImGeoNet's geometry-shaped voxel features and learns from two complementary signals: a class-agnostic 3D localization objective supervised by high-quality 3D pseudo boxes, and an open-set recognition objective by aligning 3D voxel features with diverse CLIP embeddings sampled from multi-view segments. At inference, only multi-view RGB images and camera poses are needed—no depth or CLIP forward pass— enabling efficient (~0.3 s/scene) and accurate OV 3D detection.
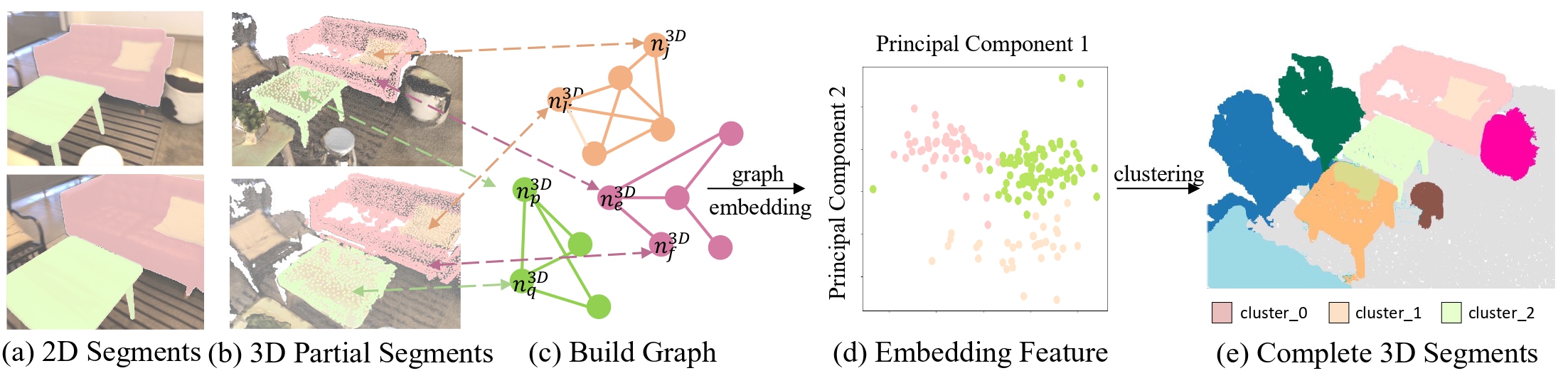
3D Pseudo Box Generation. From posed multi-view images, we obtain 2D segments and build a cross-view association graph using geometric consistency (epipolar constraints, depth checks) and appearance cues. Coherent multi-view groups are merged into 3D structures, to which we fit oriented bounding boxes as pseudo boxes. These serve as high-quality training targets for a class-agnostic localization head and achieve higher precision/recall than prior methods.
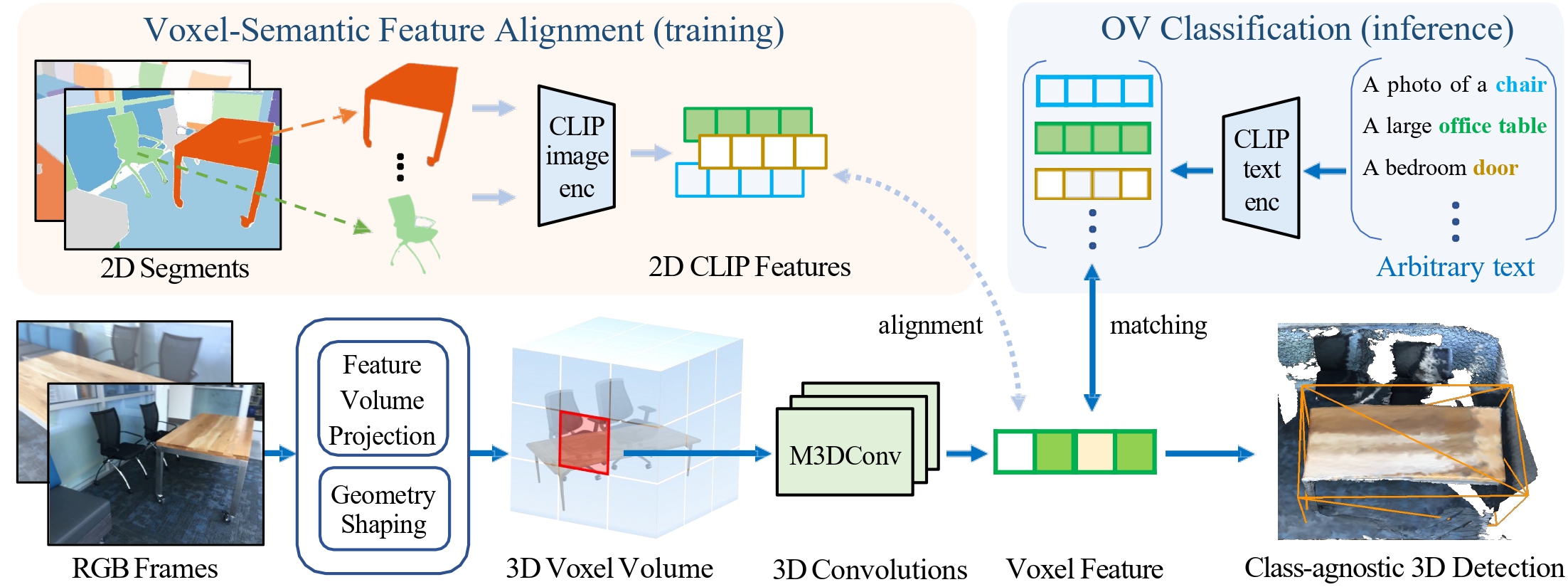
Pipeline. During training, ImGeoNet encodes multi-view images into voxel features. The detector head is supervised by (i) class-agnostic 3D localization to the generated pseudo boxes, and (ii) voxel–semantic alignment that matches voxel features to CLIP embeddings sampled from the associated multi-view segments—enabling open-vocabulary recognition in a single stage. During inference, we predict 3D boxes and OV scores directly from multi-view RGB and camera poses without depth or CLIP computation, providing both accuracy and speed.